

##Working with XML files in Python Based on original materials by Greg Wilson and Andrew Walker
Introduction
XML is becoming the standard way to store everything from web pages to astronomical data. There is a bewildering variety of tools for dealing with it. In this tutorial we will look at how to process and modify XML. We will cover the basics but if you are interested here is some recommended reading:
- Castro 2002 if all you care about is HTML
- Castro 2000 if you want to know more about XML
- Harold 2004 if you want to become an expert
A bit of history (to help you understand the context).In 1969-1986 Standard Generalized Markup Language (SGML) emerged. It was developed by Charles Goldfarb and others at IBM. It was a way of adding information to medical and legal documents so that computers could process them. It had a very complex specification (over 500 pages). In 1989: Tim Berners-Lee creates HyperText Markup Language (HTML) for the World Wide Web. It was much (much) simpler than SGML. Anyone could write it, so everyone did.
The problem was HTML had a small, fixed set of tags. Everyone wanted to add new ones. So the solution was to create a standard way to define a set of tags, and the relationships between them. The first version of XML was standardized in 1998. It is a set of rules for defining markup languages, much more complex than HTML, but still simpler than SGMLNew version of HTML called XHTML was also defined, it was like HTML, but obeys all XML rules. There still is a lot of non-XML compliant HTML out there.
Formatting Rules
A basic XML document contains elements and text. Full spec allows for external entity references, processing instructions, and other fun.
Elements are shown using tags:
- Must be enclosed in angle brackets <>
####Document Structure
- Elements must be properly nested
- If Y starts inside X, Y must end before X ends
- So
<X>...<Y>...</Y></X>is legal… - …but
<X>...<Y>...</X></Y>is not
- Every document must have a single root element
- I.e., a single element must enclose everything else
- Specific XML dialects may restrict which elements can appear inside
which others
- XHTML is very liberal
- MathML (Mathematical Markup Language) is stricter
####Text
- Text is normal printable text
- Must use escape sequences to represent
<and>- In XML, written
&name;
- In XML, written
Attributes
- Elements can be customized by giving them
attributes. The attributes provide additional information about the element.
- They need to be rnclosed in the opening tag. Let's look at HTML example:
<h1 align="center">A Centered Heading</h1><p class="disclaimer">This planet provided as-is.</p>
- An attribute name may appear at most once in any element
- Like keys in a dictionary
- So
<p align="left" align="right">...</p>is illegal
- Values must be quoted
- Old-style browsers accepted
<p align=center>...<p>, but modern parsers will reject it - Must use escape sequences for angle brackets, quotes, etc. inside values
- Old-style browsers accepted
Attributes Vs. Elements
- Use attributes when:
- Each value can occur at most once for any element
- The order of the values doesn't matter
- Those values have no internal structure
- In all other cases, use nested elements
- If you have to parse an attribute's value to figure out what it means, use an element instead
###Element Tree library in Python
Python's standard library includes Element Tree library (xml.etree.ElementTree typically shortened to ET). Element Tree provides easy ways to manipulate XML documents. ET is also a widely used library so learning it will help you in working with the code written by other developers.
#####XML Tree Example XML documents have hierarchical structure so a natural way to represent them is to use a tree structure.
<root>
<first>element</first>
<second attr="value">element</second>
<third-element/>
</root>
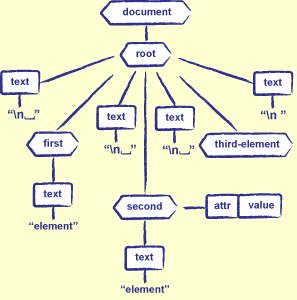
Figure 21.5: An XML Tree
#####Creating a Tree using ElementTree and extracting element object 'root'
Example: file "planets.xml"
<?xml version="1.0" encoding="utf-8"?>
<galaxy name="Solar System">
<planet name="Mercury"><period units="days">87.97</period></planet>
<planet name="Mars"><period units="days">56.97</period>
<moon name="Phobos"> </moon>
<moon name="Deimos"> </moon>
</planet>
<planet name="Venus"><period units="days">224.7</period></planet>
<planet name="Earth"><period units="days">365.26</period></planet>
</galaxy>
import xml.etree.ElementTree as etree
tree = etree.parse('planets.xml')
root = tree.getroot()
print root.attrib
Listing all root's children
for child in root:
print "tag=",child.tag, " attrib=",child.attrib
Elements are stored as a list so we can access the children using list indexes:
print root[0].tag, root[0].attrib
In ElementTree the attributes are stored as dictionaries:
print child.attrib['name']
####Finding particular elements:
We know now how to get hold of all elements in the XML document by recursively extracting all the children using the for loop. But the ET library comes with methods which allow for iterating over the elements immediately below a given element. The iter method does exactly that (using "depth-first iteration (DFS)"). iter method is available for both ElementTree and Element objects.
Using iter for ElementTree:
for element in tree.iter():
print element.tag, element.attrib
Using iter for Element:
for element in root[0].iter():
print element.tag, element.attrib
We can use iter to find particular element:
for element in root.iter(tag= 'period'):
print element.attrib
print element.text
Or
for element in root.iter(tag='moon'): print element.attrib
print element.text